Plenty of apps nowadays include a feature to share your live location with designated people, for a variety of reasons. I’ve personally found live location sharing on Uber and Messenger invaluable for meeting up with friends—no more “how many blocks away are you?”—while others have found it useful as a security feature, so trusted friends know where they are on their trip or hangout.
One of the more interesting implementations of this feature is the one in Google Maps: instead of providing your location for a specific itinerary or for a block of 60 minutes, Maps can actually allow the other person to see exactly where you are, forever (or until you turn the sharing off). It’s pretty neat and integrates into the app as smoothly as one would imagine—I can just pull up Google Maps, zoom out, and see pins where certain of my friends are right now, just as I can find my favorite trailhead or halal cart marked on the globe. It’s useful for safety reasons, and also for a group of friends exploring a new city to find each other after wandering off a few separate ways. But to a set of my friends who like to travel the globe, the main appeal is in being able to know if someone else happens to be in the same city who might be down for an impromptu meetup.
There are two things I’d change to make it more useful for this latter use case, though:
It should be more accessible. I don’t want to have to individually invite specific friends to have access to this feature. On their side, it’s a bit of a commitment to accept the invite and permanently welcome a big-ass pin on their Google Maps; on my side, it’d feel like I’m picking favorites.
It needn’t be so precise. I don’t really care for my friends to know exactly which bathroom stall I’m pissing in, but it would be nice for them to see what city or general region I’m around. This is an even bigger issue if I do make it accessible to more than just close friends, obviously.
The Interface
Conveniently, my homepage already had a whole section dedicated to mapping locations. It’s a world map in the Mercator projection with my travel and residential history since 2013 plotted out as arcs and dots. (Getting the functions right for transforming latitude and longitude to pixel coordinates was actually a fun little task a few years ago. There’s plenty to be said about issues with representation in Mercator, but it does make for some tidy equations when figuring out where to stick a marker.) This would be the perfect place for a current-location indicator.
With the venue chosen, the next step was to design the indicator. I’d always been a fan of cyberpunk aesthetics; one of my hobbies is spending all day on a nifty cyberpunk interface that doesn’t actually do very much. So the first thing that came to mind was this radar blip:
Something about pulsating dots really makes them irresistible. Source: SkotosStudio via YouTube.
A whole scanner beam might be excessive, but it does feel nice to have two complementary components that build up that “pulsing” sensation. The first is the “core,” which feels a little bit like a bouncing ball seen from above, with opposite timing functions on the “grow” and “shrink” phases:
The second is the “nova,” which keeps expanding as it fades away:
Of course, we still need it to look okay in browsers that don’t support animations, so we make sure that it’s still recognizable without them:
Putting it all together, this is what the Blip looks like:
The Data
Now I faced a conundrum: where would this data come from, and how would it get onto my homepage?
The second question shouldn’t have been hard, but I’d already committed myself to keeping it free of client-side code as part of my useless crusade against JavaScript, one of my favorite languages. Furthermore, the page was a static file generated by Cleverly, which meant I couldn’t run any server-side code, either. In the end, I settled on a stupid hack to update the tag on the live page using a cron job. (Hey, that’s what this category is for.)
As for data retrieval, it would’ve made sense for the location to be pulled from my device location on Google Maps, but Maps doesn’t appear to have a public API. (Fair enough.) Luckily, I did have a more accessible method of geolocation thanks to the Tasker Tracker project I wrote about in the last post: every time I record my activity, my current coordinates get logged to Google Sheets.
The easiest way to get this info off would be through one of Google’s client libraries, but I took this as an opportunity to get familiar with OAuth by handling the requests myself. Google still documents their OAuth handshake process to support “limited-input devices,” so I pretended I was a smart TV and followed that guide.
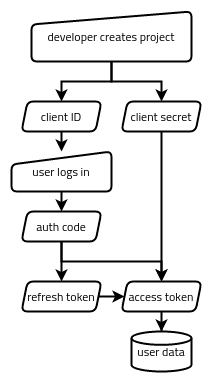
In the end, Google’s OAuth wasn’t very difficult to work with. There are basically five strings being passed around in one way or another:
The client ID, which identifies the application as a whole (like a username for the application).
The client secret, which authenticates the application as a whole (like a password for the application).
The authorization code, which represents a single user (me) authorizing the app to access something specific (my Google Sheets data).
The refresh token, which represents that authorization having not been revoked.
The access token, which is what actually gets traded for the data we want (my Google Sheets data).
If you’re curious about building something similar, the whole process looks something like the following:
Via the Google Cloud Platform web interface, create a GCP project, enable the Google Sheets API for it, and set up an OAuth client ID and client secret pair. This gets stored in a box (somewhere accessible to the app but inaccessible to the public).
Our app generates a special Google auth link, which the user uses to authorize the app (via a web interface). This gets the authorization code passed back to the app.
Our app trades the authorization code for a refresh token and an access token. These get stored in our metaphorical box, too.
Our app tries to use the access token to access the data. If it’s expired, it trades the refresh token for a new access token and tries again.
From that point on, we should only have to keep running step 4 to get the data we need. If the refresh token is no longer valid (such as if the app’s permission to access that user’s data gets revoked), we start back at step 2. If the GCP project’s own credentials get revoked, we start back at step 1.
Here are the two APIs I ended up accessing for this project:
João Dias’s guide to setting up Google Sheets API access in Tasker (which incidentally is another “limited-input device”) was a great resource for the first few steps above, in addition to helping me set up the data recording in Tasker Tracker to begin with.
The code to retrieve and update the Blip’s location can be found here.
I’ve posted before about my love for tracking and quantifying daily life. It’s a hobby I’ve kept up in one form or another since 2013, when I first started tracking my sleeping hours and caffeine intake as a college freshman in order to calculate a so-called “coffee-to-sleep ratio.” (This was something of a statistical El Dorado that lived on the lips of college students; as far as we know, caffeine is no substitute for sleep.)
There’s nothing quite like the satisfaction of rolling up three months’ worth of data into a single pretty chart that shows exactly how I’d been living my life, followed by a few minutes of self-absorbed pondering just what does that trend line mean? The exercise isn’t always useful; much of the time, all that comes out of the pipeline is a series of beautiful plots of trends I already suspected and personal failings I already knew I had. But once in a while, the sight of my small wins and insecurities, digitized and laid bare in all their damning glory, is enough to motivate a real change of habit.
Easy.
These are the pleasures I’d like to introduce to you with the Tasker Tracker project. (If you’re feeling too lazy to read the rest of this intro, here’s a direct link to the tool.)
What’s It For and How Do I Use It?
Let’s get a few definitions out of the way:
Tasker is a general-purpose automation app for Android. (Think of it as IFTTT or Zapier, but cheaper and more useful for individual users; in fact, this project started as a set of IFTTT recipes that quickly outgrew what IFTTT was capable of.) For example, Tasker can be configured to perform an action when you tap on a button or walk into a building. As of this writing, the app costs $3.49 on the Play Store.
Google Sheets is a free spreadsheet app with a powerful charts interface. I use it for all my tracking because it’s so easy to play around with visualizations and manipulate the data in new ways.
Tasker Tracker is an online tool for generating Tasker configs for logging data to Google Sheets.
Tasker Tracker can track all sorts of stuff. Here are a few ideas:
What you have for breakfast each day (Spam, Eggs, Ham)
What mood you’re in throughout the day (on a scale of 1 to 5)
What you’re doing throughout the day (Eating, Exercising, Playing, Sleeping, Socializing, Working)
One of several configs I have set up on my phone’s home screen, this one is for time tracking.
For example, you might be interested in keeping a log of what you have for breakfast in the morning, along with when and where you have your breakfast. With a Tasker Tracker config defined with a list of possible breakfast foods as options, all you’d need to do is tap a single button on your phone at breakfast, and Tasker handles the rest.
The Great Demotivator: Effort
I started this project after deciding a year ago to track how I spend my time. Unlike tracking things such as sleep and finances, time tracking requires vigilance: I need to remember to record what I’m doing as I’m doing it, or else I’d forget about some of my activities by the time I actually get around to writing them down.
The biggest threat to maintaining this vigilance is the effort involved. If it took me a few seconds each time to select (or, God forbid, type) an activity every hour, I’d soon get lazy and drop the habit. Tasker Tracker is meant to make the task as stupid simple as possible. All I have now are a set of buttons on my phone’s home screen that I tap once an hour to record what I’d been doing for that hour, and everything else flows through a mass of data-processing formulae on Google Sheets.
No, I’m not telling you what the colors mean.
Why Is Everything So Shiny?
I read about a trend in product design called neumorphism and it sounded cool. I have no regrets.
This post is part of a series diving into the concepts behind the Stupid CSS demo page, a collection of interactive elements implemented in pure CSS at various levels of absurdity. Check it out on GitHub!
The Internet is full of wonderful things. No matter what obscure hobby you get yourself into, there’s probably an online community out there with all the answers you need, the drama you don’t, and a cast of friendly strangers who have dedicated far more of their lives and have much stronger opinions on the deepest nuances of the topic than you have. It’s a humbling reminder of both what massive numbers of people there are in the world and just how weird they all are.
Two of the online communities I’m involved in are the calculator community and the quantified-self community. The first is a group of graphing calculator enthusiasts who pour their heart and soul into making games for an outdated device that teaches math. The latter obsesses over ways to measure everything about our daily lives and slap it on a graph. (So many people worry about Uncle Sam or Big Tech getting their grubby hands on our private data; meanwhile, some of us are out here thinking that our private data ought to be shared, analyzed, and made into art.)
Times and relative sizes of my bowel movements by day.
You might say I’m a bit of a numbers guy—or, in the parlance of our times, a fucking nerd.
What Big Mama is not, as far as I can tell, is obsessively quantified and data-driven. Imagine my surprise, then, when I discovered that there is one topic in which the mamasphere shares my enthusiasm for hardcore data-viz proliferation: baby names.
Toms, Dicks, and Harrys
Few things have so completely saturated the blogosphere as have baby names.
Many of the blogs I went through while reading up for this post had an article along the lines of “how I named my baby,” some with helpful graphics. Scary Mommy has a whole section dedicated to baby names with lists spanning cultures and centuries, although some of its etymologies are dubious at best. (No, “Barde” is not a “Chinese moniker” that means “someone who sings ballads.” It’s “bard” with an E.) Searching “baby names” on Google turns up a billion or so results from family resources, government entities, and ever-so-helpful corporate blogs. Even the Social Security Administration gets in on the act, digging through its venerable database of … uh, everyone … to provide tables of name popularity by year.
In any case, it’s an understandable subject to obsess over. Names are labels to our identities and wield immense power in mythologies and traditions the world over. These beliefs are still palpable today, from the fairy tale of Rumpelstiltskin to the many English Bible translations that euphemize the tetragrammaton—and all its power—into a simple, small-caps “Lord.” (Arthur C. Clarke’s “The Nine Billion Names of God” is a modern take on a tradition as old as history; it’s also simply one of my favorite sci-fi short stories.)
The topic has been debated in sociology as well. Some research claims to find that a person’s name can have real effects on their life. They cite such effects as the Portia Hypothesis, which states that female lawyers with traditionally masculine-sounding names are more likely to become judges. Others—like the 2005 pop-sociology bestseller Freakonomics—say otherwise.
Miles Per Hour and Hours Per Hour
And digging into baby name trends does produce some fascinating results.
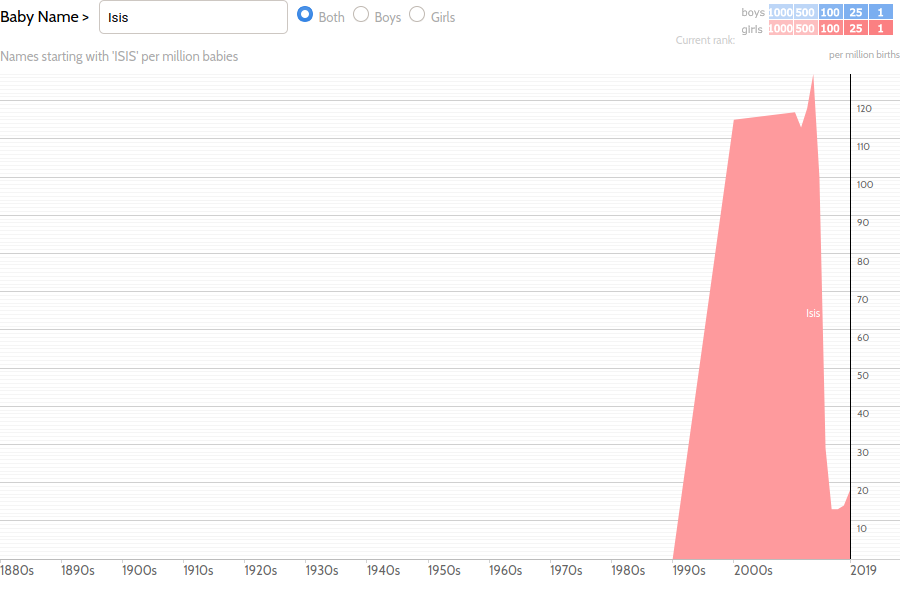
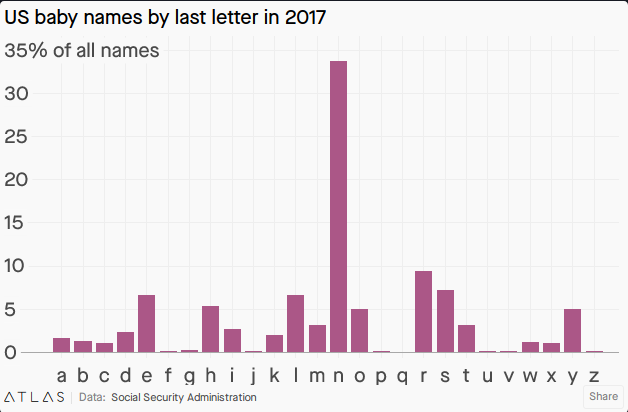
Some naming trends carry the unmistakable influence of pop culture, which gave rise to the Bellas and Jakes of two decades ago and the Finns and (somewhat premature) Daeneryses of the last. On the other hand, the number of children named “Isis” dropped precipitously after a certain terrorist organization started taking over swathes of the Middle East.
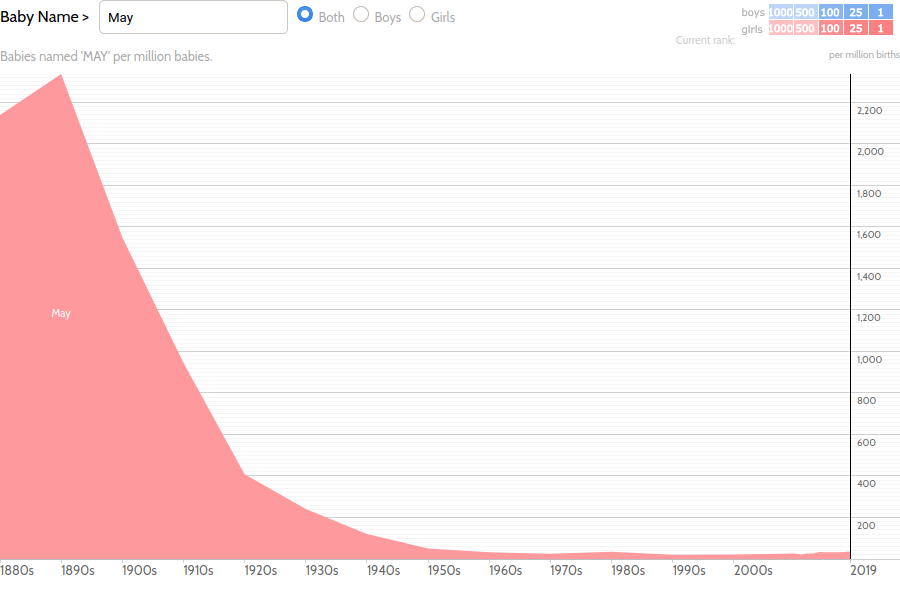
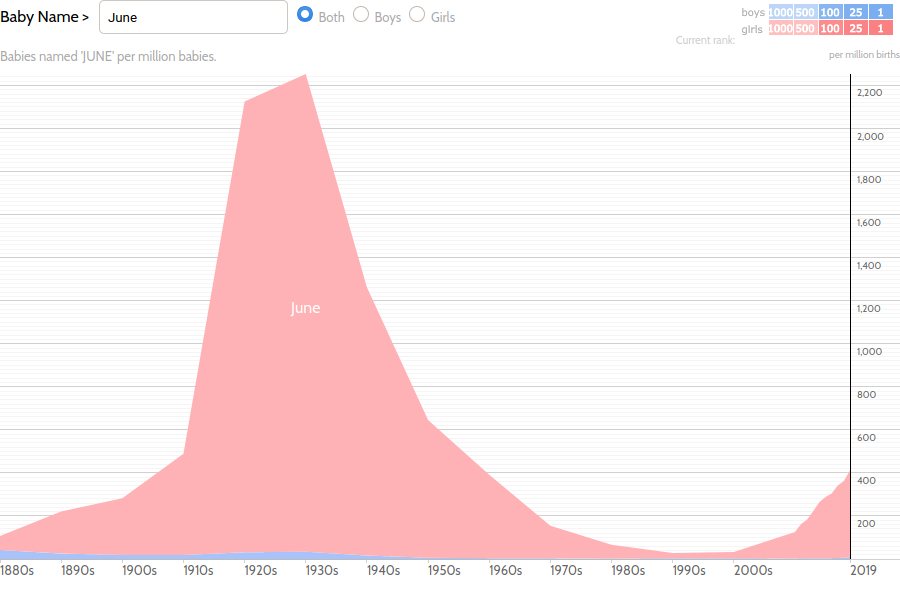
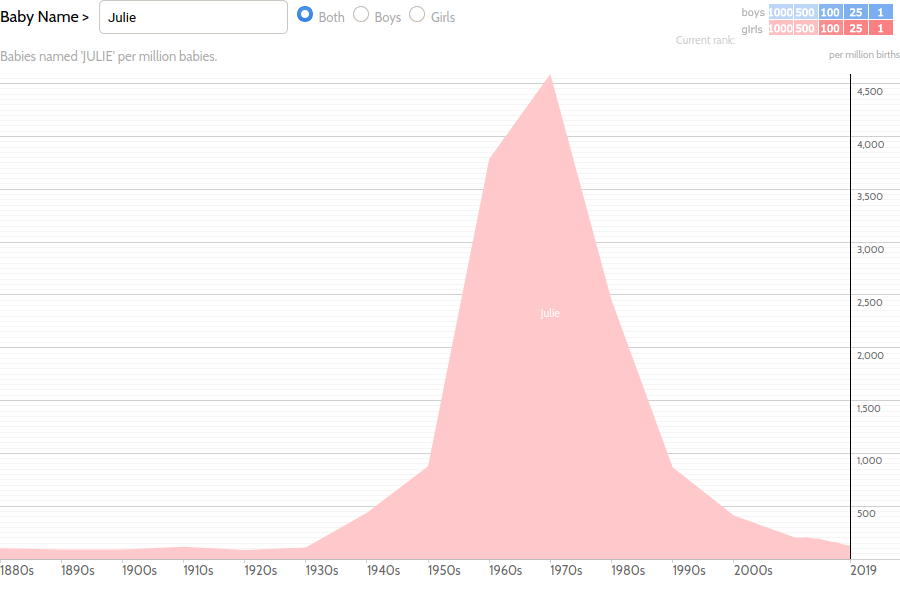
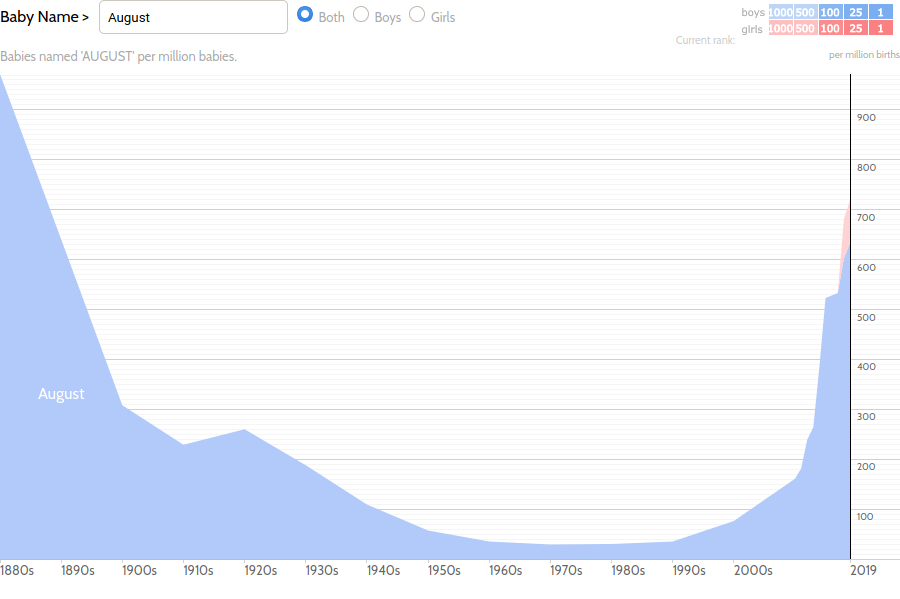
This last chart inspired me to dig a little deeper into some of the more temporary fads. Of the months of the year, May, June, July (as “Julie,” which I can only assume is a typo), and August are reasonably common names. Take a look at the years in which these monikers were common:
A clear pattern emerges: as the months of the year progress, so do the decades in which they are popular as a name. “May” was most popular around 1890, “June” around 1930, “Julie” around 1970, and “August” around 2010. (The latter was also coming off a craze at the end of the 19th century, which makes sense as the months tend to repeat themselves.) Evidently, months become names at a rate of about one month every 40 years, or 0.002.
Expect this graph to peak around 2050. Source: Baby Name Wizard.
This post is part of a series diving into the concepts behind the Stupid CSS demo page, a collection of interactive elements implemented in pure CSS at various levels of absurdity. Check it out on GitHub!
One of my favorite thing to do with code has always been making it do what it’s not meant to do. My first experience with programming was on a graphing calculator, making games that were progressively grosser abuses of a math-teaching device; maturing into other areas of software development, I’ve carried with me that attitude of making the most satisfying interface out of the fewest resources possible. It’s part consideration for not-so-high-end client machines (including my own), part self-imposed challenge to keep things interesting.
A fun way to apply this challenge in web development is to build an interactive site without JavaScript. It’s useful, too: Not only does invoking the JavaScript engine incur a bit more network and processing power to run a webpage, but it also excludes users who can’t run scripts in their browser at all, whether for performance reasons, hardware limitations, or privacy concerns. Giving old, JavaScript-less browsers as close to the full experience as possible is the ultimate form of graceful degradation.
Organic JavaScript-Free Eggs
That got me thinking: What’s something quintessentially JavaScript that I could attempt to recreate in CSS?
An event handler.
In particular, a dblclick (double-click) event handler would be something particularly stupid in CSS. Not only does CSS not have any notion of events—the :hover, :checked, and other pseudo-classes being selectors of state—it also doesn’t have any way to express time intervals, much less to condition behavior on the passage of a certain amount of time. These two ingredients are exactly what make up a double-click event, after all: two clicks occurring on the same element within a threshold time interval.
As it turns out, CSS does—sort of—have a way to describe time intervals. It’s just wrapped up in a neat little CSS3 module called CSS Animations.
<marquee /> Is Dead, Long Live <marquee />
Animations in CSS are a way to describe how CSS properties should change with time. They’re similar to CSS Transitions, which describe how properties transition from one state to another, usually smoothly. The difference is that animations are much more powerful, allowing us to do such things as repeat, pause, or set keyframes on the animation.
Sprinkling on some transitions can make it feel more slick:
If you’re not into the whole subtlety thing, adding animations can really spice it up:
Many properties in CSS can be animated. Most relevant to us are the properties of position: top, right, bottom, and left.
Accessibility Issues
As you can gather from the last demo above, a terrible animation can make it hard to click what would otherwise be a straightforward button. What if we used that to our advantage?
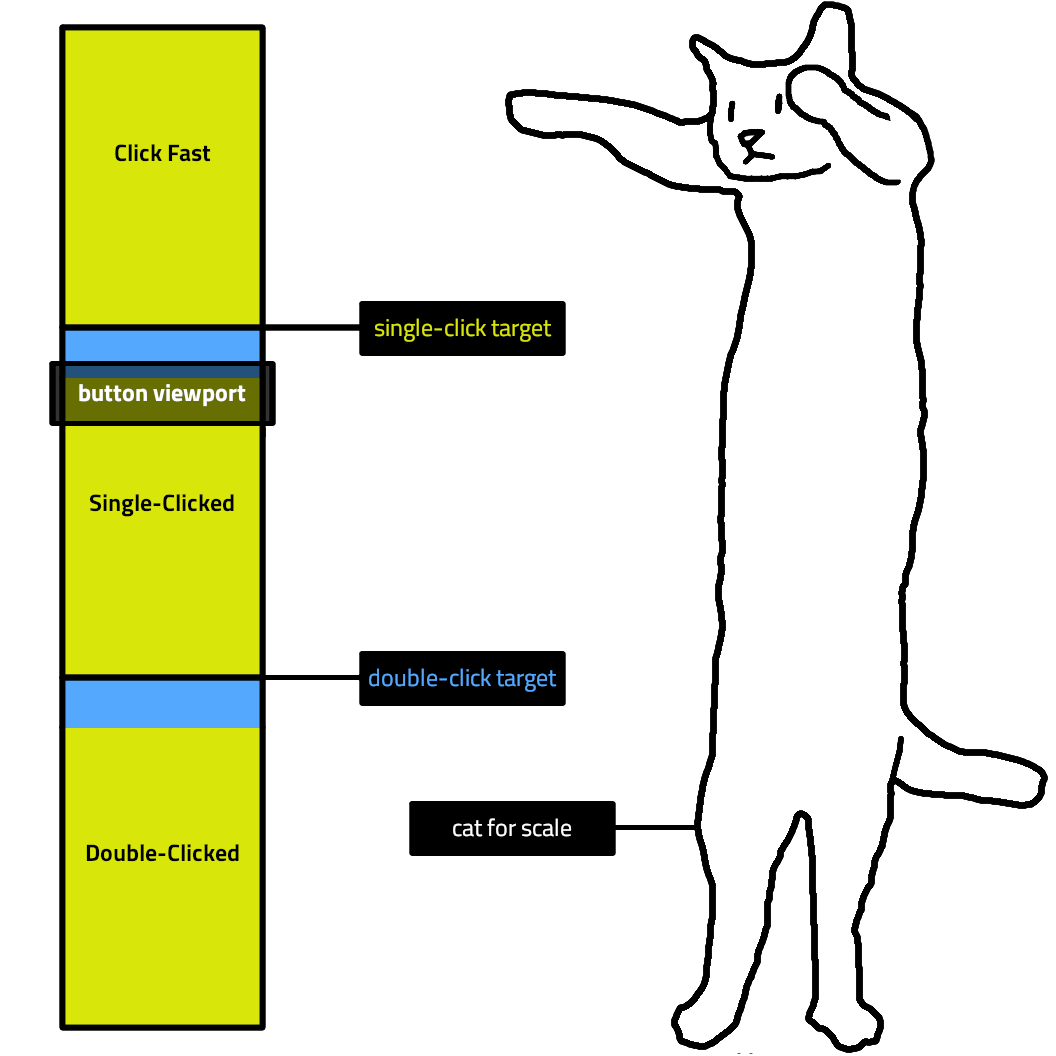
Here’s the big idea: When the user clicks on a button, we give them a small amount of time—400 milliseconds seemed about right from trial and error—before an intervening animation makes it not just hard but impossible to click the next button in the sequence. If the user manages to click a second time before the 400 milliseconds are up, we congratulate them on performing a double click. Otherwise, they get left in the single-click zone.
Voilà.
The way it works is that the button you see is actually just a viewport into an absurdly long column 4,800,000 pixels high. This giant column is split equally into three zones: the “Click Fast” zone, the “Single-Clicked” zone, and the “Double-Clicked” zone. Each of the Single-Clicked and Double-Clicked zones starts with a 400-pixel tall block, both of which link to the Double-Clicked zone; the rest of these two zones, as well as the entirety of the Click Fast zone, link to the Single-Clicked zone.
With a CSS animation on the top property, this whole column is constantly zooming upwards relative to the button viewport at a rate of 1,333 pixels per second.
The demo starts off with the button viewport showing the top of the Click Fast zone. A single click takes the user to the top of the Single-Clicked zone (at the top of the first blue section). What happens next depends on how quickly the user performs a second click:
If the second click comes quickly enough after the first (as on the left side of the recording), it happens on the double-click (blue) element and the user is taken to the top of the Double-Clicked zone.
Otherwise (as on the right side of the recording), it happens on the single-click (yellow) element and the user is left at the top of the Single-Clicked zone.
Hash/Tag Problems
The way these blue and yellow elements jump to the tops of their respective target zones takes advantage of the fact that linking to a fragment scrolls to the target even if the target is in an unscrollable parent, which makes it seem like the page is loading new content on the fly.
This is my favorite way to create dynamic content on pages without JavaScript—it’s similar to a technique sometimes termed the checkbox hack, but it works in a much wider array of browsers, including ones from the last century. (Check out my write-up of the File Browser demo for an in-depth look at this effect and how it can be used for pure-CSS dynamic galleries compatible with Internet Explorer 5!)
Unfortunately, this approach carries a few problems that leave the demo with much to be desired:
Because we want the label of the current zone to show up in the middle of the button regardless of how far into the zone we’ve scrolled, it needs to be position: fixed. This means that the button needs to be in a predictable location on the page (so the page can’t scroll) and that this location needs to be calculable using CSS units (so the button can’t flow with text).
The only content that can be conditionally shown has to be inside the button, so while we can have a neat demo where the button’s label reflects the fact that a double-click took place, we can’t use it to control anything else. So much for a double-click handler.
Although Internet Explorer 10 and 11 support all of the features required by the demo, they also treat double clicks on a link as a single click, so it actually takes three clicks within 400 milliseconds to get the “Double-Clicked” label to show up.
The State Machine
Avoiding the checkbox hack also doesn’t do us much good since none of the browsers it excludes (i.e., Internet Explorer 8 and earlier) support CSS Animations anyway, so I went ahead and rebuilt the demo using hidden radio buttons:
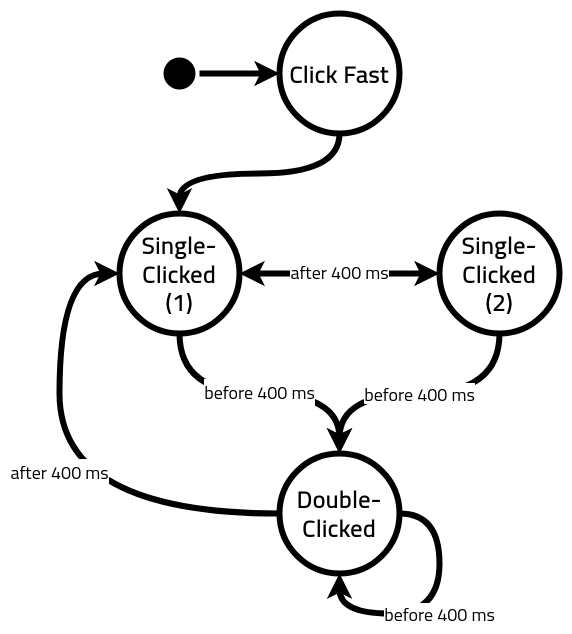
This version is a bit simpler to explain. There are three radio buttons set to display: none and four sets of labels: one for “Click Fast,” two for “Single-Clicked,” and one for “Double-Clicked.”
When either of the first two radio buttons is selected, the button shows one of the Single-Clicked labels.
When the third radio button is selected, the button shows the Double-Clicked label.
When none of the radio buttons are selected (on the initial load), the button shows the Click Fast label.
As soon as the selected radio button changes, the newly loaded label gives the user 400 milliseconds to click and toggle the double-click radio button before the label is replaced with a visually identical one that toggles one of the single-click radio buttons. (Since we don’t need things to scroll upwards anymore, I set this animation to animation-timing-function: step-end, which makes the transition instantaneous.) The reason there are two single-click radio buttons is that only a change in which radio button is selected can trigger the animation to run again, so each of the Single-Clicked radio buttons needs to be able to trigger the other. Otherwise, the user would never leave the single-click state after the 400 milliseconds are up.
This whole business can be summarized in one small state machine:
Each post has a color-coded tab to indicate the category it belongs to.
What Happened to ClrHome?
It’s still around!
ClrHome is the site I’ve been running for the last decade or so, alongside ACagliano, who’s taken up the mantle of posting most of the recent updates. It’s been my outlet for posting about calculator projects and programming resources for calculator programmers. Nothing’s changing over there—I’ll still update ClrHome when I make progress on calculator stuff—but I’ve wanted a separate blog for a while where I can post about my broader interests.
In no way do I advocate or encourage cheating in academic environments. References to businesses in this post are not endorsements, recommendations, or referrals; if anything, take them as warnings.
I was fortunate enough to attend a university where academic integrity relied heavily on the actions and the attitudes of students.
Collaboration on homework was encouraged, as long as the solutions you wrote were your own. Attendance was never mandatory, unless class discussions were involved. It was not only a norm but a requirement that exams be unproctored: instead of seating a class of students at the end of the term to watch them do their finals, instructors generally distributed the exams to be completed on the students’ own time, along with a self-imposed time limit and a due date. Often, an exam just felt like an extra-long homework assignment with no collaboration allowed.
It’s a very different model from the way most colleges conduct their courses. Caltech is not unique in this regard, but using an honor code to this degree, to entrust the integrity of each student’s grade almost completely to every other student’s honesty—classes were often curved—is not a common approach.
I swear this image will be relevant later and I’m not just putting it here to keep you engaged. Source: Amazon.
And we were grateful for it. Being able to take exams in our own preferred environments, whenever we felt most comfortable doing so, helped ease the stress of taking high-stakes exams, though it didn’t make the exams themselves any easier. We’d all left questions blank on many a final. Class-average exam scores were often abysmal. People still failed classes. But in a cruel way, it was a sign that the system worked, that despite the obvious difficulty of their assignments, students still held themselves accountable to be honest about their ability.
Coronavirus Curricula
There is some evidence to support the effectiveness of honor codes. As an alternative to more draconian measures like the threat of expulsion which increase the cost of cheating, it reduces the cost of not cheating and allows students’ own values—not to mention their need to collaborate with peers on other assignments—to take a larger role in their choices. In an environment where students trust that other students aren’t cheating, they no longer need to cheat just to play on a level field. In short, it’s to render irrelevant this question posed to the New York Times:“If My Classmates Are Going to Cheat on an Online Exam, Why Can’t I?”
It’s also made the transition to remote learning in the current global crisis just a little smoother. With a global pandemic pushing students and professors out of the classroom, many universities are facing a problem that Caltech has had ingrained in its policies for years: how do you conduct a test without proctors? Not all universities have given up on proctored exams, much to some students’ chagrin. But for many others, it’s an uncharted territory in which they’ve been thrust by a tiny global circumstance that’s already disrupted every other part of our lives.
The suddenness and pervasiveness of the situation has already inspired a flurry of articles and analyses on ways universities should adapt their courses. Some indicate that this is the time to establish honor codes. Others say that online exams shouldn’t have time limits. (At Caltech, we referred to them as “infinite-time exams,” and I think we all had a love–hate relationship with them.) Still others call for exams to be cancelled altogether.
Regardless of the approach, these changes mean that any exams that are held would now be subject to the same avenues for cheating that normally apply only to homework and take-home writing assignments. It also means that the pandemic environment didn’t really create a new market for companies catering to students looking to cheat. Instead, it made an existing business much more valuable: instead of only helping with homework assignments, the cheating economy can now take care of exams that could be worth 50% or more of a course grade.
Homework for Hire
The cheating economy is a 21st-century phenomenon of businesses that provide students with anything from answers to homework assignments to term papers and even a grade for the whole course. It’s as elaborate as any other industry whose potential customers number in the tens of millions and isn’t technically illegal. Companies offer freemium services on homework answers and experiment with different pricing models. There are blogs dedicated to ranking and reviewing essay-writing services. Startups rise and fall.
The companies that actually provide these services often cover themselves with a veneer of propriety, either by carefully avoiding any references to cheating or by explicitly stating that using their services for cheating is not condoned. Sometimes, they even show different content to students and teachers (more on this later). But everyone knows better. As this candid review of Nerdify points out, the existence of their “honor code”—a common feature among websites in the cheating economy—simply means that “they’re not responsible for the possible repercussions” of getting caught using their services.
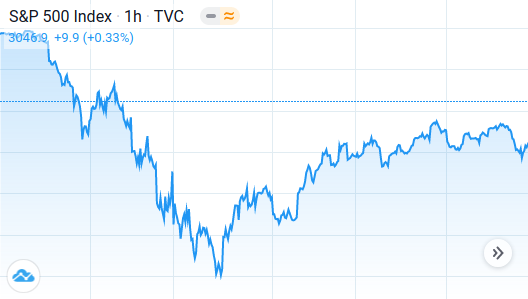
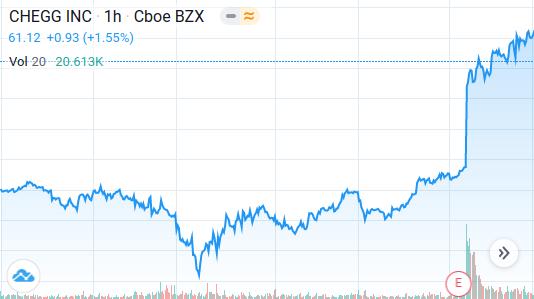
And business is booming. With students now taking all their classes and exams online, there’s more of an opportunity to use online resources and more of a reason to pay for answers. Between mid-March and mid-May, the S&P 500 gained about 10% as it started recovering from the COVID-19 dip. Over the same period, the stock price of Chegg—perhaps the most prominent of the homework-help companies—more than doubled.
An interesting feature of businesses engaged in activities that aren’t very palatable to the general public—such as essay-for-hire services—is that they face a particular challenge when it comes to growth: they need more people to know that they exist, but only the right people and nobody else. To most companies, advertising money spent on unlikely conversions is—at worst—money down the drain. To these businesses, it’s money spent actively undermining their own interests.
To put this into concrete terms, let’s consider Essays & Co., a small endeavor looking to provide completed term papers to overstressed students. They’ve found some localized success at a single school—perhaps a college their young founders are attending—but are looking to grow. As with any rowdy new upstart, Essays & Co. would like to get the word out and bring more students into its customer base. Normally, brand awareness would be their first success metric, with plenty of tried-and-true methods of achieving it at their disposal—product placement, billboards, TV spots, and so on. But unlike a normal business, Essays & Co. doesn’t want to tell everyone about their product. Doing so would invite regulatory scrutiny, parental rage, and countermeasures by suspicious teachers that negate the product’s own value.
It’s not hard to see the third issue in particular as an existential threat to Essays & Co. “Digital arms races,” in which two competing interests attempt to out-code, outmaneuver, and undermine each other, have become an established pattern in tech fields ranging from ad-blocking software to state-sponsored surveillance malware. In each case, two parties trade blows by updating their own software to be just a little cleverer each time, bypassing any new checks introduced by the other side’s iteration—a vortex of slightly more benign-looking ads, slightly more diligent ad blockers, slightly better obscured trackers, slightly more aggressive security teams.
It’s a costly process, one that can quickly drain away engineering hours—so costly, in fact, that it was cheaper for Google (in the ad-blocking case) to just pay the ransom. Getting into a mess like this could spell the end for our little essay-writing company.
This is where targeted digital advertising comes into the picture.
Sniper Marketing
In general, the strategy of advertising narrowly to customers for whom it would make a difference—such as in targeted sidebar ads—is known as pull marketing. This is in contrast to push marketing, in which the goal is to carry a message to as broad a swath of the population as possible—such as on a billboard or TV spot. This is not a novel concept, nor is pull marketing uniquely a digital phenomenon: for example, posting a flyer about an oil-change business on the window of an auto-parts store would be cross-promotion, a form of traditional pull marketing.
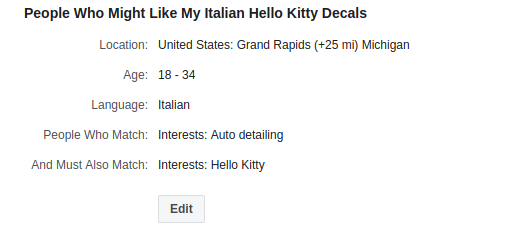
What companies like Google and Facebook have provided to their business customers, then, is not so much a new way of thinking about advertising as a radically efficient means of applying that thinking. Thanks to the incredible amount of data that these companies collect about their users, a customer can target not just people who are interested in maintaining their car—as in the flyer example above—but young people who are interested in maintaining their car, like Hello Kitty, and speak Italian.
There’s got to be someone. Source: Facebook.
(An aside: I don’t really buy the characterization of Google and Facebook as companies that “sell your data” because it implies a more nefarious business than the one they actually conduct. They hold plenty of information about us, but it’s used to carry advertisers’ messages to us, not to provide it to the advertisers. Nobody’s paying Facebook money to learn what hobbies we have; we don’t accuse the USPS of “selling our locations” when they deliver parcels. How much did working at Facebook shape my opinion on this matter? Who knows.)
The pinpoint precision of the Internet giants’ advertising engines has led to controversy in the past. In 2019, Facebook was slapped with a discrimination lawsuit after the Department of Housing and Urban Development found that a combination of the ability to buy certain types of ads on the platform (for housing) and the ability to target those ads to exclude certain groups of people (by affinity to an ethnicity or national origin) led to ads served in violation of the 1968 Fair Housing Act. A few years prior, a study found that identifying a Google user with one gender or another results in different offerings of employment ads—a recipe for equal-opportunity violations.
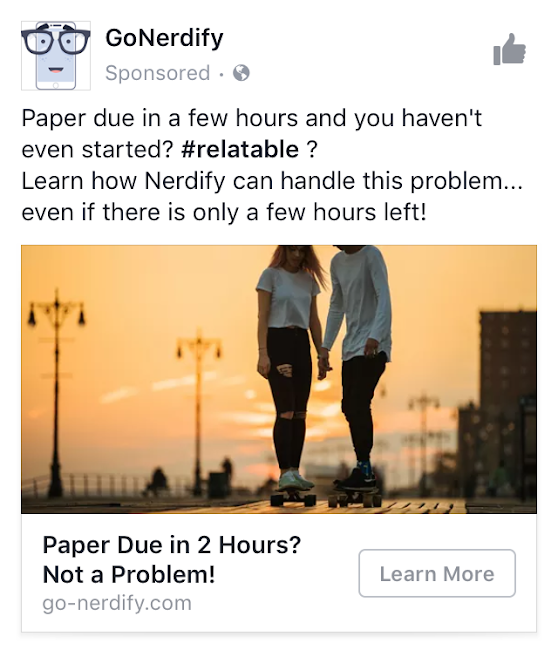
This is a real ad I got as a college student. Source: Nerdify via Facebook.
Nonetheless, numerous businesses—cheating-economy or otherwise—benefit from targeted digital advertising. The colossal success of Google and Facebook is a testament to the value of identifying customers who might be swayed by advertisements, precisely separating them from the rest, and then putting all the eggs (in this case, advertising dollars) into their basket. For Essays & Co., the need is even stronger.
We Know Who You Are and Where You’ve Been
But even the precise targeting offered by the massive online advertising platforms can’t prevent the word from reaching people the company doesn’t want to reach. Students might let slip or report on these services to their teachers. Diligent educators might look up these services for themselves, to keep themselves informed and ahead of dishonest students.
So it begins.
Fortunately for Essays & Co., there are ways to control even information spreading by word of mouth.
There are two pieces of web technology that are particularly relevant here: fingerprinting and indexing. Fingerprinting is a set of techniques that allow websites (and, by extension, the companies that run them) to uniquely identify their visitors. By combining signals such as your browser version, screen size, time zone, and even which fonts and browser extensions you have installed, companies can track which pages get accessed by someone with that unique combination—you—on their site and even across other sites. Indexing describes a process in which a program (known as a crawler or robot) builds an index of known sites by loading pages, scanning for links, loading those pages, and so on. It’s how services like Google build their massive records of keywords and webpages, reconstructing the landscape of the Internet in a way that makes searching possible.
In tandem, these two concepts allow us to ensure that one set of users—say, students—see one set of pages, while another set—teachers—see a completely different set.
This isn’t just a hypothetical scenario. Nerdify is a real-life Essays & Co. founded in 2015 (though it would claim otherwise for plausible deniability). This appears to be exactly how it approached marketing in its early years, and their model offers an excellent glimpse into how such a configuration works.
First, we create two sets of pages. One set is for the students and can describe in moderate detail how one would use the service to cheat. The other is for the teachers, and should appear more benign. (In Nerdify’s case, the first site was located at go-nerdify.com and the second at gonerdify.com, without the hyphen.)
Second, we advertise heavily and specifically to college students through Facebook. Our ads take them to the students’ site, and when they get there, the site uses their browser fingerprint to verify that they’re in the right demographic before showing the more explicit references to cheating.
Third, we use crawler instructions to prevent Google and other search engines from indexing the students’ site while actively promoting the teachers’ site to the same search engines. This way, people who find our service on their own, by search, only ever come across the teachers’ site.
Abusing robots.txt for Fun and Profit
Crucially, the third step—strategic indexing—relies on a little file called robots.txt. This is a standardized file that allows a website to tell crawlers what they are and aren’t allowed to index. Take a look at the robots.txt files that Nerdify used for its student-friendly and teacher-friendly sites:
In the first, Nerdify is instructing all crawlers to avoid the entire site (signified by /). In the second, Nerdify explicitly allows the entire site to be crawled (with the exception of two utility folders), and even offers a helpful sitemap for the crawlers to get their bearings.
The result—at least in theory—is a clean segregation of visitors into two camps. A large number of students discover Nerdify through Facebook ads and read about how they can pay for their homework to go away. Some of them sign up. Others move on. A few zealous ones report the service to their teachers, who investigate the situation with concern. The teachers search for “Nerdify” on Google, only to find a service that offers “book delivery.” Suspicion evaporates and money is made.
Arguably, web technology and the remote learning opportunities it provides saved higher education programs while COVID-19 ravaged the world. We’ve been forced to seriously consider a mode of learning that had been adopted mostly by university extension programs and struggling, oft-criticized for-profit schools. But if this has been a trial by fire of massive-scale distance learning, the ruling seems to hold that some incarnation of online learning, likely integrated with traditional classrooms, is here to stay.
And with the “new normal,” as people seem to be calling it, the role of the cheating economy continues to grow. The landscape of web technology evolves rapidly, and so do the companies that were born to exploit it.
So what can we do? We’ve seen that purely technical solutions are fragile and can be quickly defeated—plagiarism-checking software by essays on demand, digital proctoring software by a wholehostofdifferentmethods—and that the big names in the industry are plenty savvy when it comes to legal pretext and tech tricks.
In the end, I don’t think the approach should be any different from what it’s always been: by structuring courses and student relationships to reduce the pressure to cheat, rather than by trying to appeal to morality or to catch the cheating after the fact. There probably isn’t a single right answer, but we do have plenty of promising pathways and now a wealth of time with an unwitting natural experiment by which to try them out. After all, we’re all here to learn, aren’t we?








{kind=link}
{kind=link}