The Blip: On My Quest to Create a Minor Personal Security Risk
Plenty of apps nowadays include a feature to share your live location with designated people, for a variety of reasons. I’ve personally found live location sharing on Uber and Messenger invaluable for meeting up with friends—no more “how many blocks away are you?”—while others have found it useful as a security feature, so trusted friends know where they are on their trip or hangout.
One of the more interesting implementations of this feature is the one in Google Maps: instead of providing your location for a specific itinerary or for a block of 60 minutes, Maps can actually allow the other person to see exactly where you are, forever (or until you turn the sharing off). It’s pretty neat and integrates into the app as smoothly as one would imagine—I can just pull up Google Maps, zoom out, and see pins where certain of my friends are right now, just as I can find my favorite trailhead or halal cart marked on the globe. It’s useful for safety reasons, and also for a group of friends exploring a new city to find each other after wandering off a few separate ways. But to a set of my friends who like to travel the globe, the main appeal is in being able to know if someone else happens to be in the same city who might be down for an impromptu meetup.

There are two things I’d change to make it more useful for this latter use case, though:
- It should be more accessible. I don’t want to have to individually invite specific friends to have access to this feature. On their side, it’s a bit of a commitment to accept the invite and permanently welcome a big-ass pin on their Google Maps; on my side, it’d feel like I’m picking favorites.
- It needn’t be so precise. I don’t really care for my friends to know exactly which bathroom stall I’m pissing in, but it would be nice for them to see what city or general region I’m around. This is an even bigger issue if I do make it accessible to more than just close friends, obviously.
The Interface
Conveniently, my homepage already had a whole section dedicated to mapping locations. It’s a world map in the Mercator projection with my travel and residential history since 2013 plotted out as arcs and dots. (Getting the functions right for transforming latitude and longitude to pixel coordinates was actually a fun little task a few years ago. There’s plenty to be said about issues with representation in Mercator, but it does make for some tidy equations when figuring out where to stick a marker.) This would be the perfect place for a current-location indicator.
With the venue chosen, the next step was to design the indicator. I’d always been a fan of cyberpunk aesthetics; one of my hobbies is spending all day on a nifty cyberpunk interface that doesn’t actually do very much. So the first thing that came to mind was this radar blip:
A whole scanner beam might be excessive, but it does feel nice to have two complementary components that build up that “pulsing” sensation. The first is the “core,” which feels a little bit like a bouncing ball seen from above, with opposite timing functions on the “grow” and “shrink” phases:
The second is the “nova,” which keeps expanding as it fades away:
Of course, we still need it to look okay in browsers that don’t support animations, so we make sure that it’s still recognizable without them:
Putting it all together, this is what the Blip looks like:
The Data
Now I faced a conundrum: where would this data come from, and how would it get onto my homepage?
The second question shouldn’t have been hard, but I’d already committed myself to keeping it free of client-side code as part of my useless crusade against JavaScript, one of my favorite languages. Furthermore, the page was a static file generated by Cleverly, which meant I couldn’t run any server-side code, either. In the end, I settled on a stupid hack to update the tag on the live page using a cron job. (Hey, that’s what this category is for.)
As for data retrieval, it would’ve made sense for the location to be pulled from my device location on Google Maps, but Maps doesn’t appear to have a public API. (Fair enough.) Luckily, I did have a more accessible method of geolocation thanks to the Tasker Tracker project I wrote about in the last post: every time I record my activity, my current coordinates get logged to Google Sheets.
The easiest way to get this info off would be through one of Google’s client libraries, but I took this as an opportunity to get familiar with OAuth by handling the requests myself. Google still documents their OAuth handshake process to support “limited-input devices,” so I pretended I was a smart TV and followed that guide.
In the end, Google’s OAuth wasn’t very difficult to work with. There are basically five strings being passed around in one way or another:
- The client ID, which identifies the application as a whole (like a username for the application).
- The client secret, which authenticates the application as a whole (like a password for the application).
- The authorization code, which represents a single user (me) authorizing the app to access something specific (my Google Sheets data).
- The refresh token, which represents that authorization having not been revoked.
- The access token, which is what actually gets traded for the data we want (my Google Sheets data).
If you’re curious about building something similar, the whole process looks something like the following:
- Via the Google Cloud Platform web interface, create a GCP project, enable the Google Sheets API for it, and set up an OAuth client ID and client secret pair. This gets stored in a box (somewhere accessible to the app but inaccessible to the public).
- Our app generates a special Google auth link, which the user uses to authorize the app (via a web interface). This gets the authorization code passed back to the app.
- Our app trades the authorization code for a refresh token and an access token. These get stored in our metaphorical box, too.
- Our app tries to use the access token to access the data. If it’s expired, it trades the refresh token for a new access token and tries again.
From that point on, we should only have to keep running step 4 to get the data we need. If the refresh token is no longer valid (such as if the app’s permission to access that user’s data gets revoked), we start back at step 2. If the GCP project’s own credentials get revoked, we start back at step 1.
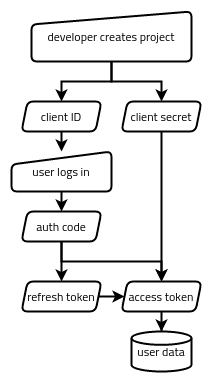
Here are the two APIs I ended up accessing for this project:
João Dias’s guide to setting up Google Sheets API access in Tasker (which incidentally is another “limited-input device”) was a great resource for the first few steps above, in addition to helping me set up the data recording in Tasker Tracker to begin with.
The code to retrieve and update the Blip’s location can be found here.
-
2 Comments on The Blip: On My Quest to Create a Minor Personal Security Risk